
前言
有一天,我从家里后院挖出来一台双路E5服务器,洗干净发现还可以用,但不知道应该跑些啥,索性就跑一个之前没怎么尝试过的内容——AI绘画
相对来说,AI绘画并不需要特别强的时效性,不会像LLM模型那样需要即时回复的算力,所以对于我来说,一边做着自己的事,另一边让服务器自己默默的去跑,并不是很在乎它到底需要多长的时间
服务器部分配置:E5-2680v4 X2,64G DDR4,500G SSD,NO GPU
本文将以Ubuntu 24.04,Stable Diffusion WebUI v1.10.1,AnythingXL Beta5模型为例,由于服务器并不在我身边,我无法提供在满负载下服务器的噪音和温度,当然应该不会有人把服务器放在需要安静的地方吧
起步
1.安装必要环境
连接上你的服务器,并取得ROOT用户权限,更新部分软件包
sudo apt update
sudo apt install -y python3 python3-venv python3-dev git wget
sudo apt install -y build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev curl libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
sudo apt install -y libgl1 libglib2.0-0 libsm6 libxrender1 libxext6
Stable Diffusion WebUI的推荐Python版本为3.10,而Ubuntu 24.04系统默认安装了Python 3.12,所以我们需要 pyenv 来安装其他版本的Python
首先创建一个名为 webui 的用户来运行WebUI,默认不允许以ROOT用户运行,通过以下指令创建并切换到一个无密码的用户
sudo useradd -m -s /usr/sbin/nologin webui
sudo usermod -s /bin/bash webui
sudo -u webui -i
在 webui 用户下安装 pyenv
curl https://pyenv.run | bash
#安装完成后,通过以下命令将pyenv添加到环境变量,逐条运行
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init --path)"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
exec "$SHELL"
运行 pyenv --version 检验安装成功,创建一个Python版本为3.10.6的虚拟环境并激活
pyenv install 3.10.6
pyenv virtualenv 3.10.6 webui
pyenv activate webui
2.拉取Stable Diffusion WebUI项目和模型
在 webui 用户下,拉取项目
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
修改适用于 CPU-Only 环境的参数和库,编辑项目目录中的 webui-user.sh 文件,添加以下内容
export COMMANDLINE_ARGS="--skip-torch-cuda-test --use-cpu all --no-half --opt-sdp-attention --precision full"
export TORCH_COMMAND="pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu"
注意:如果你的服务器网络受限,请注意替换pip,gitclone等下载源的镜像链接以加快下载
保存后运行目录中的 webui.sh 启动WebUI,第一次启动成功后会拉取一个默认模型,稍后可以删除
拉取模型,Civitai并不提供拉取功能,我们需要手动获取直链
打开 万象熔炉 | Anything XL - XL | Stable Diffusion XL Checkpoint | Civitai 并注册一个账户,然后点击模型页面的 Download ,等待浏览器拉起下载,我们将下载链接复制下来,不需要让浏览器下载,直接取消即可,通常是一个 CloudFlare R2存储桶的链接
在命令行中下载模型,注意替换你的下载直链
cd models/Stable-diffusion
wget "your-direct-url" -O AnythingXL_xl.safetensors
3.优化与启动
双路E5 2680v4总线程数为56,需要设置环境变量来使Stable Diffusion调用全部线程以发挥CPU最大性能,编辑项目文件夹下的 webui-user.sh
在底部追加以下内容
export OMP_NUM_THREADS=56
export MKL_NUM_THREADS=56
export OPENBLAS_NUM_THREADS=56
export NUMEXPR_NUM_THREADS=56
export VECLIB_MAXIMUM_THREADS=56
提示:一些其他文章中建议不要设置为所有线程,各线程调度之间会有性能损失,经过我的实际测试下来,在应用32线程和56线程时分别生成同一个768x1280的图片时,所需的时间分别为9min20sec和7min46sec,如果你的服务器还有其他服务正在运行,请注意保留一定的性能
不需要使用 xformers 或 --medvram 等优化功能,因为这些只对 GPU 有效,注意经常监测你的服务器的温度和负载等运行状态,以防高负载对硬件造成伤害
设置好后就可以启动了,运行 webui.sh 等待加载完成后,打开本地链接 http://127.0.0.1:7860 即可,运行时你可以在ROOT用户下使用 htop 命令来监测各个线程的负载情况 (如未安装 htop 使用 apt install htop 来安装)
成品欣赏
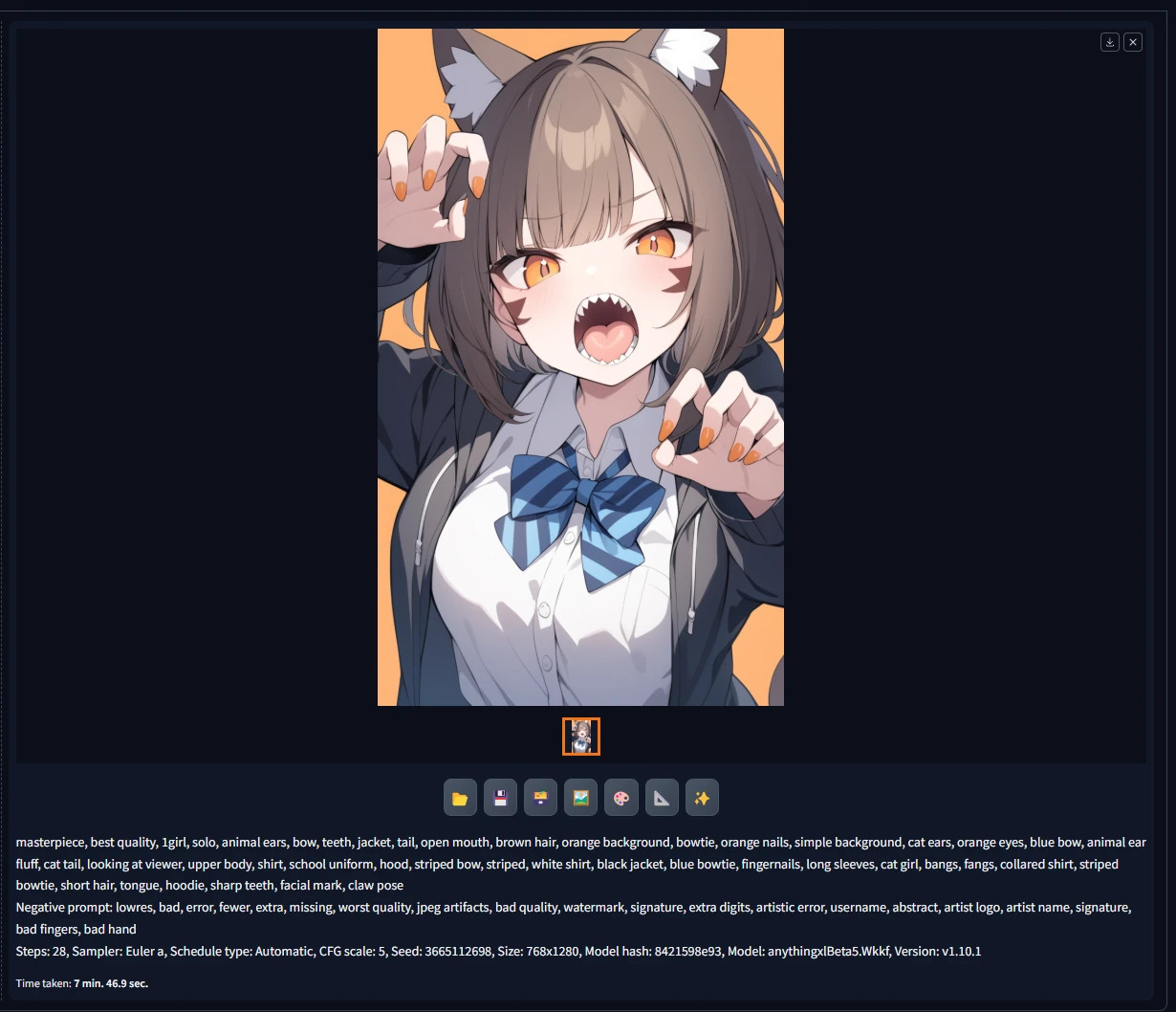
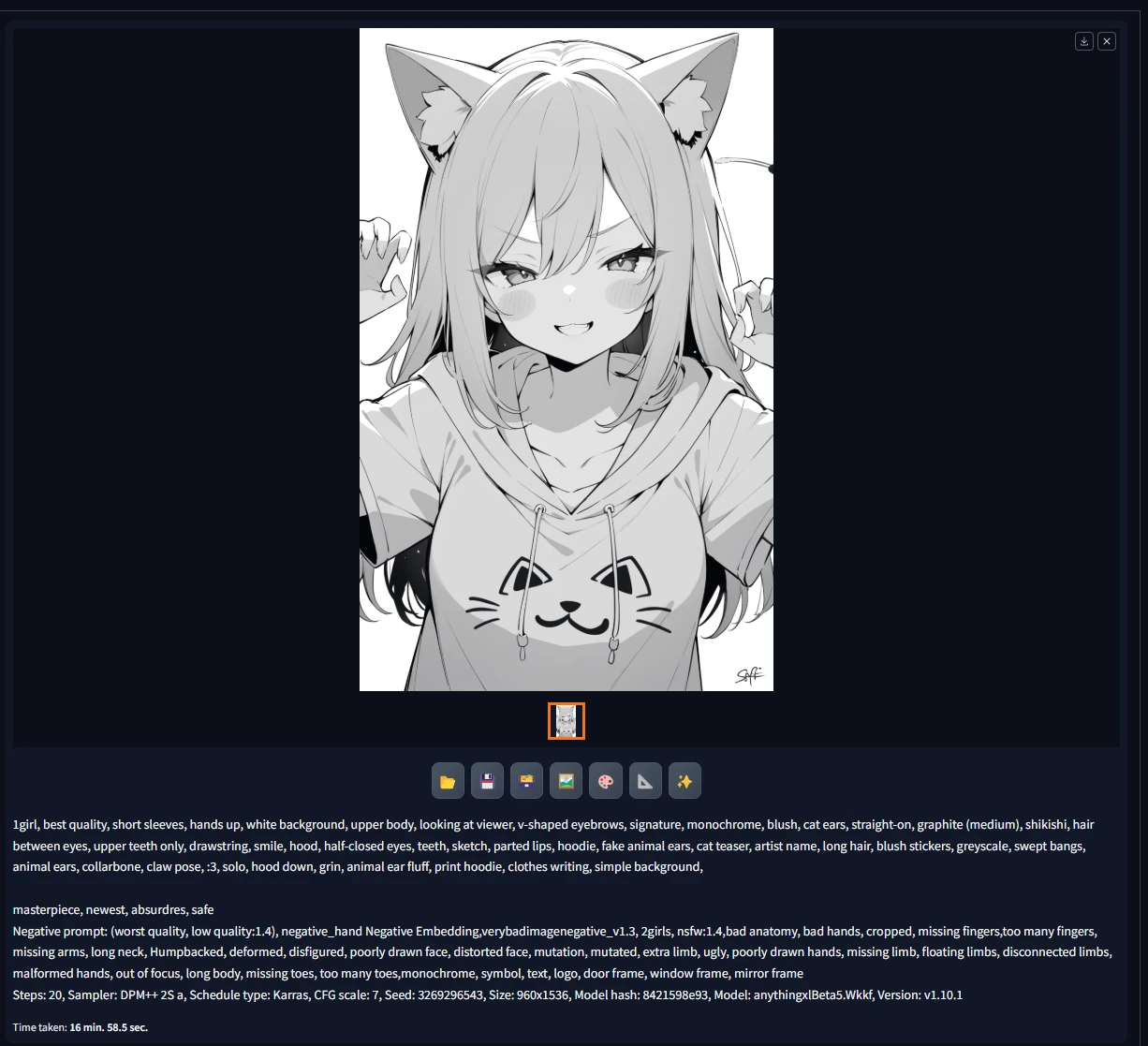
Prompt来源 万象熔炉 | Anything XL - XL | Stable Diffusion XL Checkpoint | Civitai
常见问题
1.Tokenizers报错
AnythingXL模型需要 openai/clip-vit-large-patch14 模型依赖,不过在新版本的WebUI似乎不会自动下载这个模型,请在启动前加入以下环境变量以开启下载
export force_download=True
如果你的服务器网络受限,注意替换 Huggingface 等平台的镜像链接,例如 export HF_ENDPOINT=https://hf-mirror.com
结语
没有GPU也没有关系,用CPU也是能跑的,本文可能没有涵盖到所有可能的错误,如果你有什么解决不了的问题欢迎讨论
版权
本文章隶属于 DDverse ,遵循 © CC BY-NC-SA 4.0 协议,如需转载请保留来源并在必要的时候告知我